RNN & LSTM (Vanishing Gradient, Exploding Gradient)
Recurrent Neural Networks (RNN)
$$h_t = \tanh (W_{hh}h_{t-1} + W_{xh}x_{t})$$

Backpropagation Through Time (BPTT)
기존의 신경망 구조에서는 backpropagation 알고리즘을 이용한다. RNN에서는 이를 살짝 변형시킨 버전인 Backpropagation Through Time (BPTT) 을 사용하는데, 그 이유는 각 파라미터들이 네트워크의 매 시간 스텝마다 공유되기 때문이다. 즉, 각 시간 스텝의 출력단에서의 gradient는 현재 시간 스텝에서의 계산에만 의존하는 것이 아니라 이전 시간 스텝에도 의존한다.
RNN 장단점
- RNN 장점
- 어떤 길이의 입력이라도 처리할 수 있다.
- 긴 길이의 입력이 들어와도, 모델의 크기가 커지지 않는다.
- (이론적으로) step $t$에 대한 계산은, 이전 단계의 정보를 포함한다.
- RNN 단점
- Recurrent 연산이 느리다. (not parallelized)
- 현실적으로, 오래 전 step의 정보에 접근하기 어렵다.
- 기울기 소실 (Vanashing Gradient)이 발생할 수 있다.
- 역전파 과정에서 입력층으로 갈수록 기울기가 점차 작아지는 현상.
- 입력층에 가까운 층들에서 가중치들이 업데이트가 제대로 되지 않으면 최적의 모델을 찾을 수 없게 된다.
- 기울기 폭주 (Exploding Gradient)이 발생할 수 있다.
Vanishing Gradient가 발생하는 이유
활성화 함수로 흔히 사용되는 sigmoid 함수와 tanh 함수의 도함수는 아래와 같다. 도함수의 최대값이 1보다 작은 것을 확인할 수 있다.

역전파 (back-propagation) 과정에서 활성화 함수의 미분값이 사용되는데, 1보다 작은 값이 반복해서 곱해지면 0에 수렴하게 된다.
Why is Vanishing Gradient a Problem?
먼 거리의 gradient signal은 가까운 거리의 gradient signal보다 훨씬 작기 때문에 손실된다.
따라서 먼 거리의 gradient signal은 모델 가중치에 영향을 끼치지 못하고, 모델 가중치는 가까운 거리의 gradient signal에 대해서만 업데이트된다.
Exploding Gradient가 발생하는 이유
Back propagation 연산에는 Activation function의 편미분 값뿐만 아니라 가중치 값들도 관여하게 된다.
만약, 모델의 가중치들이 충분히 큰 값이라고 가정을 하면, 레이어가 깊어질수록 충분히 큰 가중치들이 반복적으로 곱해지면서 backward value가 폭발적으로 증가하게 된다. 이를 Exploding gradient라 한다.
Why is Exploding Gradient a Problem?
Gradient가 너무 크면, SGD update step이 커지게 된다.
너무 큰 step으로 업데이트를 수행하여 잘못된 매개변수 구성에 도달하면, 큰 손실이 발생하여 잘못된 업데이트가 발생할 수 있다.
How to fix vanishing/exploding gradient problem?
- Two new types of RNN
- LSTM
- GRU
- Other fixes for vanishing (or exploding) gradient:
- Gradient clipping
- 그라데이션의 norm이 threshold보다 큰 경우, SGD 업데이트를 적용하기 전에 크기를 줄이는 방법
- Skip connections
- Gradient clipping
- More fancy RNN variants:
- Bidirectional RNNs
- Multi-layer RNNs
Long Short-Term Memory (LSTM)
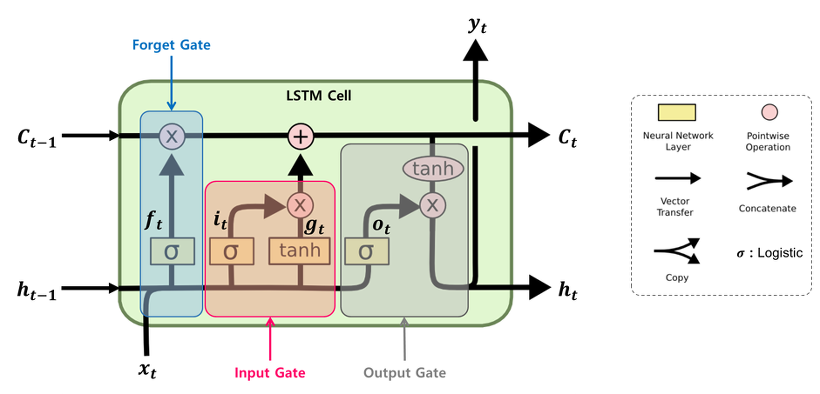
- LSTM의 사용 이유
- RNN은 데이터의 장기 의존성(long-term dependency)을 학습하는 데 어려움을 겪지만, LSTM은 더 긴 long-term 시퀀스를 처리할 수 있도록 만들어졌다.
- LSTM은 Memory Cell과 Gate를 사용하여 장기 및 단기 Hidden State를 통과한다.
- Cell state를 도입하면서 gradient flow가 방해 받지 않게 하며, gradient가 잘 흘러가지 않는 것을 막아준다.
LSTM의 각 Gate들의 역할
1. Forget Gate ($f_{t}$)
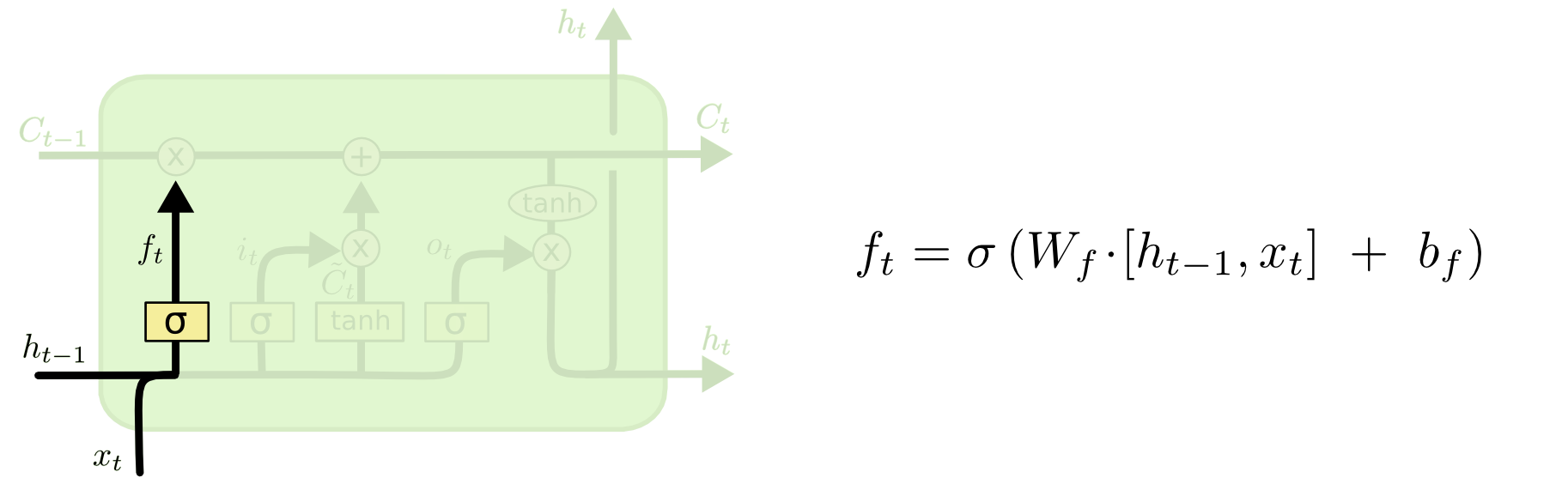
- 과거 정보를 얼마만큼 유지할 것인가?
- Forget Gate는 cell state에서 sigmoid($\sigma{}$) layer를 거쳐 이전 hidden state를 얼마나 기억할지 정한다.
2. Input Gate ($i_{t}$)
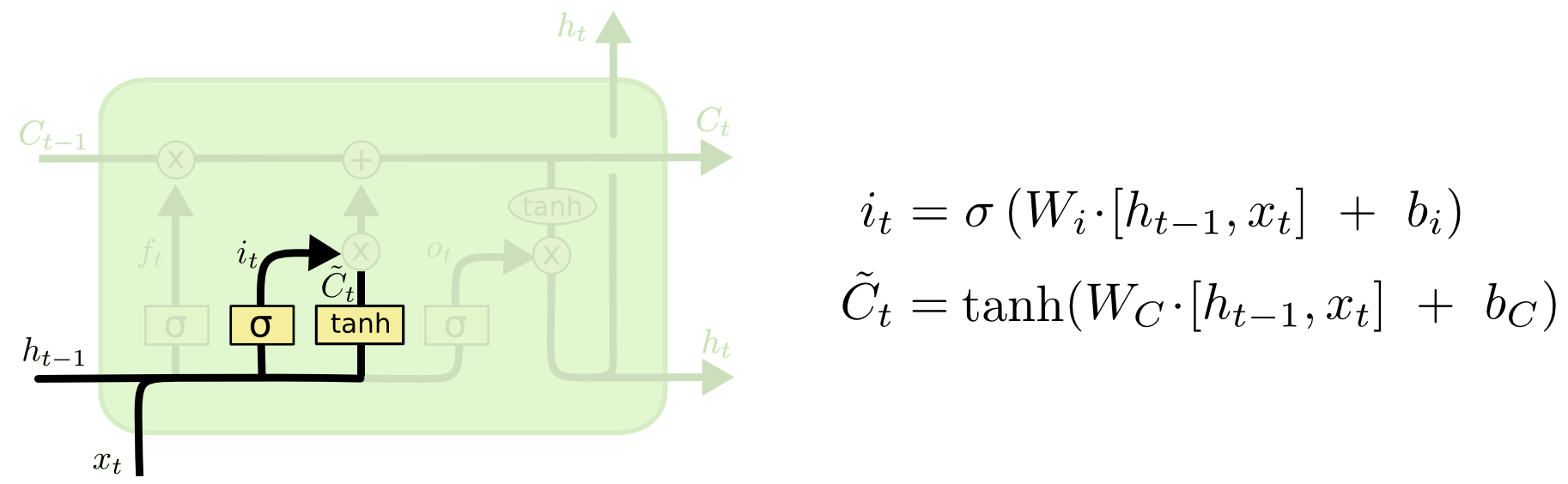
- 새로 입력된 정보는 얼마만큼 활용할 것인가?
- Input Gate는 새로 입력된 정보 중 어떤 것을 cell state에 저장할 것인지를 정한다. 먼저 sigmoid($\sigma{}$) layer를 거처 어떤 값을 업데이트 할 것인지를 정한 후, $\tanh$ layer에서 새로운 후보 Vector를 만든다.
- 활성화함수로써 sigmoid를 쓰지 않고, $\tanh$를 쓰는 이유는 여기 참고
3. Output Gate ($o_{t}$)
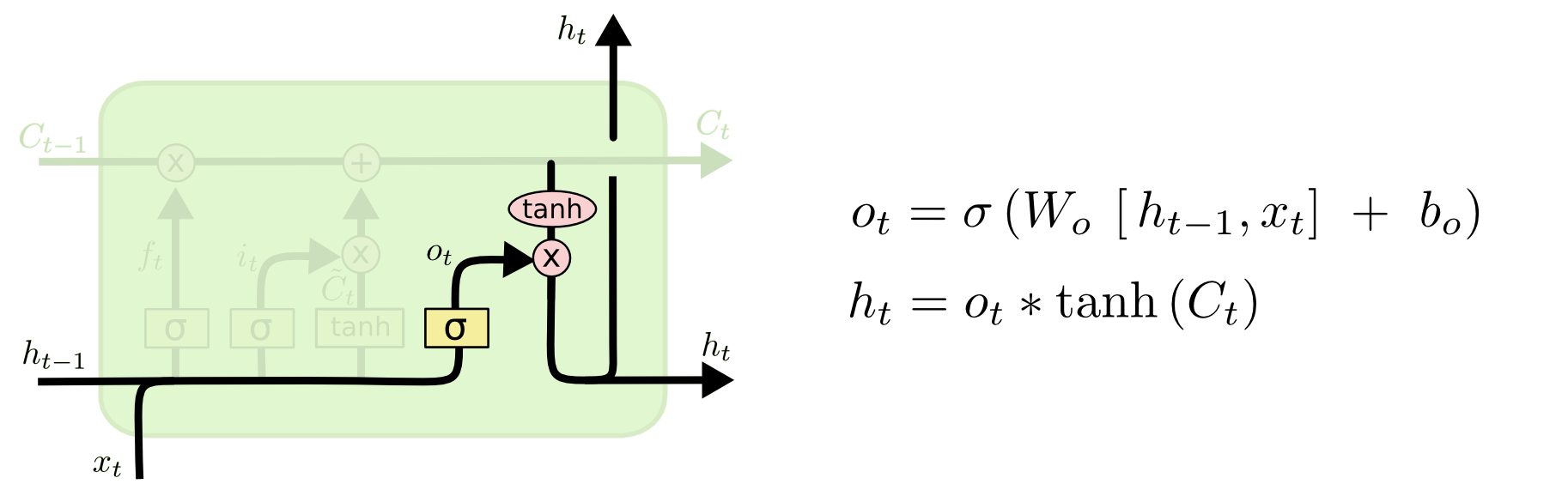
- 두 정보를 계산하여 나온 출력 정보를 얼마만큼 넘겨줄 것인가?
- Output Gate는 어떤 정보를 output으로 내보낼지 정한다. 먼저 sigmoid($\sigma{}$) layer에 input data를 넣어 output 정보를 정한 후 Cell state를 $\tanh$ layer에 넣어 sigmoid($\sigma{}$) layer의 output과 곱하여 output으로 내보낸다.
References
- 인공지능 응용 (ICE4104), 인하대학교 정보통신공학과 홍성은 교수님
- Stanford CS224N - NLP w/ DL | Winter 2021 | Lecture 5 - Recurrent Neural networks (RNNs)
- [머신러닝/딥러닝] 10-1. Recurrent Neural Network(RNN)
- RNN Tutorial Part 2 - Python, NumPy와 Theano로 RNN 구현하기
- Neural Network Notes
- (2) 활성함수와 순전파 및 역전파
- Vanishing gradient / Exploding gradient
- LSTM(Long-Short Term Memory)과 GRU(gated Recurrent Unit)(코드 추가해야함)
- 07-07 기울기 소실(Gradient Vanishing)과 폭주(Exploding) - 딥 러닝을 이용한 자연어 처리 입문
- LSTM - 인코덤, 생물정보 전문위키
- [딥러닝] LSTM 쉽게 이해하기 - YouTube
- Loner의 학습노트 :: LSTM 개인정리