
[논문리뷰] Adaptive-RAG: Learning to Adapt Retrieval-Augmented Large Language Models through Question Complexity
(NAACL 2024) Adaptive-RAG: Learning to Adapt Retrieval-Augmented Large Language Models through Question Complexity
arXiv : https://arxiv.org/abs/2403.14403
code : https://github.com/starsuzi/Adaptive-RAG
1. Introduction
- 논문이 다루는 task
- Open-Domain Question-Answering task with RAG (Retrieval-Augmented Generator)
- Single-hop QA: 한 문서만 필요한 질문에 답하는 것
- Multi-hop QA: 질문과 함께 거대한 지식 말뭉치(corpus)가 주어졌을 때 답을 찾기 위해 말뭉치에 다중추론 점프(홉)를 수행하여 질문에 답하는 것 (출처: LG AI연구원 Research Blog)
- Open-Domain Question-Answering task with RAG (Retrieval-Augmented Generator)
- 해당 task에서 기존 연구 한계점
- Single-hop QA와는 달리, 복잡한 Multi-hop QA는 한번의 retrieval-and-response 과정만으로는 답변이 어려움
- 예시: 'When did the people who captured Malakoff come to the region where Philipsburg is located?'라는 질문에 답하기 위해선, 4번의 reasoning steps가 필요
- 이러한 복잡한 Query를 효율적으로 다루기 위한 multi-step and multi-reasoning QA에 대한 연구가 있었음 (Retrievers와 LLMs에 여러번 반복해서 접근)
- 하지만 기존의 multi-step QA 방식은 복잡한 쿼리에는 필수적이지만, 단순한 쿼리에는 불필요한 computing overhead를 초래하므로 비효율적임
반면에 복잡한 쿼리를 single-step-retrieval이나 non-retrieval strategies로 처리하는 것은 부족함
- 저자들은 real-world scenario에서의 유저들은 항상 복잡한 질문을 하지 않는다는 점에 착안하여, 쿼리의 복잡도에 따라 operational strategies를 dynamic하게 조정하는 adaptive QA system를 제안함
- Single-hop QA와는 달리, 복잡한 Multi-hop QA는 한번의 retrieval-and-response 과정만으로는 답변이 어려움
2. Related Work
Adaptive Retrieval
- strategies를 dynamic하게 조정하는 adaptive QA system에 대한 연구들이 이미 존재함 (frequency of entities in queries 기반 방법, generated outputs from models for multi-step QA 방법)
- 전자는 지나치게 단순해서 multi-hop queries를 고려하지 못할 때가 있기도 하고, 후자는 지나치게 복잡해서 여러 모듈에 접근해야 답을 얻을 수 있음 (아래 Figure 2 참고)
- 한편, dynamic하게 text를 retrieve, critique, and generate 하는 정교한 모델도 있음 (Self-RAG)
- 저자들은 3가지 선행 연구들 모두 단일 모델에 의존하는 방법이고, 다양한 복잡성의 다양한 쿼리를 처리하는 데 있어 최적이 아닐 수 있으며, 쿼리 복잡도에 따라 가장 적합한 검색 증강 LLM 전략을 선택할 수 있는 새로운 접근 방식이 필요하다고 주장함

3. Method
Preliminaries & Notations
Non Retrieval for QA
- $\mathbf{q}$: input query from the user, $\mathbf{\bar{a}}$: generated answer from the LLM, $\mathbf{a}$: actual correct answer
- $\mathbf{\bar{a}} = LLM(\mathbf{q})$
Single-step Approach for QA
- $\mathbf{d}$: external knowledge, $\mathcal{D}$: external knowledge source (e.g., Wikipedia)
- $\mathbf{d} = Retriever(\mathbf{q}; \mathcal{D})$, $\mathbf{d} \in \mathcal{D}$
- $\mathbf{\bar{a}} = LLM(\mathbf{q}, \mathbf{d})$
Multi-step Approach for QA
- $\mathbf{q}$: initial query from the user, $i$: retrieval step, $\mathbf{d}_i$: new documents that retrieved from $\mathcal{D}$
- $\mathbf{c}_{i}$: additional context that can be composed of previous documents and outcomes $(\mathbf{d}_{1}, \mathbf{d}_{2}, \cdots, \mathbf{d}_{i-1}, \mathbf{\bar{a}}_{1}, \mathbf{\bar{a}}_{2}, \cdots, \mathbf{\bar{a}}_{i-1})$
- $\mathbf{d}_{i} = Retriever(\mathbf{q}, \mathbf{c}_{i}; \mathcal{D})$
- $\mathbf{\bar{a}}_{i} = LLM(\mathbf{q}, \mathbf{d}_{i}, \mathbf{c}_{i})$
- $Retriever$와 $LLM$의 실제 구현은 multi-step approaches마다 다르기 때문에 $\mathbf{c}_{i}$ 역시 달라질 수 있음 (none, some or all of the previous documents and answers)
Main Idea
Query Complexity Assessment
- query complexity를 결정하는 complexity classifier model을 제안함
- $o = Classifier(\mathbf{q})$
- $Classifier$는 smaller Language Model로, query complexity level $o$를 3단계로 나누어 평가
- 'A': $\mathbf{q}$ is straightforward and answerable by $LLM(\mathbf{q})$ itself
- 'B': $\mathbf{q}$ has the moderate complexity where at least a single-step approach $LLM(\mathbf{q}, \mathbf{d})$ is needed
- 'C': $\mathbf{q}$ is complex, requiring the most extensive solution $LLM(\mathbf{q}, \mathbf{d}, \mathbf{c})$
Classifier Training Strategy
query-complexity pairs에 주석이 달린 dataset이 없음 → 저자들은 Classifier을 위한 training dataset을 자동으로 구성하는 두가지 특정 전략을 제안함
- 세가지 전략 ((A) Non Retrieval for QA, (B) Single-step Approach for QA, (C) Multi-step Approach for QA) 결과를 기반으로 라벨링
- e.g., 가장 간단한 방법인 Non Retrieval 방법으로 정확한 정답을 생성한다면, query complexity level을 A로 라벨링
- 동점일 경우, 더 간단한 방법이 높은 우선순위를 가짐
- 아래 표는 각각의 방법 별 정답여부에 따른 최종 class label을 표로 직접 나타낸 것이다. 중간에 (?)로 되어있는 부분은 논문에 자세히 나와 있지 않아 뇌피셜로 예측했다.
(A) Non Retrieval (B) Single-step (C) Multi-step 최종 class label O O O A X O O B X X O C O X O A (?) O X X A (?) O O X A (?) X O X B (?) X X X unlabeled
- 남은 unlabeled를 원본 데이터셋에 따라 할당
- e.g., unlabeled query의 출처가 single-hop datasets라면 B로 할당
- e.g., unlabeled query의 출처가 multi-hop datasets라면 C로 할당
4. Experimental Setups
Datasets
- Single-hop QA
- SQuAD v1.1: 주석자가 읽은 문서를 기반으로 질문을 작성하는 과정을 통해 만들어
- Natural Questions: Google 검색의 실제 사용자 쿼리로 구성
- TriviaQA: 다양한 퀴즈 웹사이트에서 가져온 퀴즈 질문으로 구성
- Multi-hop QA
- MuSiQue: 여러 개의 single-hop 쿼리를 합성하여 2~4 hops에 걸친 쿼리를 구성하여 수집
- HotpotQA: 주석자가 여러 위키백과 문서를 연결하는 질문을 생성하도록 하여 구성
- 2WikiMultiHopQA: Wikipedia와 관련 지식 그래프 경로에서 파생되어 2-hops가 필요
Models
- No Retrieval
- Single-step Approach-based method
- Adaptive Retrieval (Mallen et al., 2023)
- 쿼리에 나타나는 엔티티가 less popular 경우에만 검색 모듈로 LLM을 적응적으로 보강
- Self-RAG (Asai et al., 2024)
- 특정 threshold 이상의 특수 검색 토큰을 예측하면 Retrieve-and-Generate를 수행
- Adaptive-RAG
- SOTA Multi-step Approach; IRCoT (Trivedi et al., 2023)
- 답을 도출하거나, maximum step에 도달할 때까지 retriever와 LLM에 CoT reasoning으로 반복 추론함 (for every query)
- Adaptive-RAG w/ Oracle classifier
- ideal scenario of Adaptive-RAG
Evaluation Metrics
Adaptive models를 평가할 때에는 performance와 efficiency의 trade-offs를 동시에 고려하는 것이 필수적임
- measure the effectiveness
- F1, EM, Accuracy
- measure the efficiency
- measure the number of retrieval-and-generate steps and the average time for answering each query relative to the one-step approach
Implementation Details
- Retriever
- BM25 (Mallen et al., 2023 및 Trivedi et al., 2023과 통일)
- Generator
- FLAN-T5 series models (XL with 3B parameters and XXL with 11B parameters)
- GPT-3.5 model (gpt-3.5-turbo-instruct)
- External document corpus
- dataset type에 따라 다른 sources 사용
- single-hop datasets: Wikipedia corpus preprocessed by Karpukhinet al. (2020)
- multi-hop datasets: preprocessed corpus by Trivedi et al. (2023)
- Query-Complexity Classifier
- T5-Large model (770M parameters)
- 100 training iterations까지 Validation Set에서 가장 좋은 성능을 보이는 epoch 사용
- Learning Rate: 3e-5, Optimizer: AdamW, Loss: Cross Entropy Loss
- 6개 데이터셋에서 400개의 쿼리를 샘플링
- computing resources
- A100 GPUs with 80GB
5. Experimental Results and Analyses
Main Results
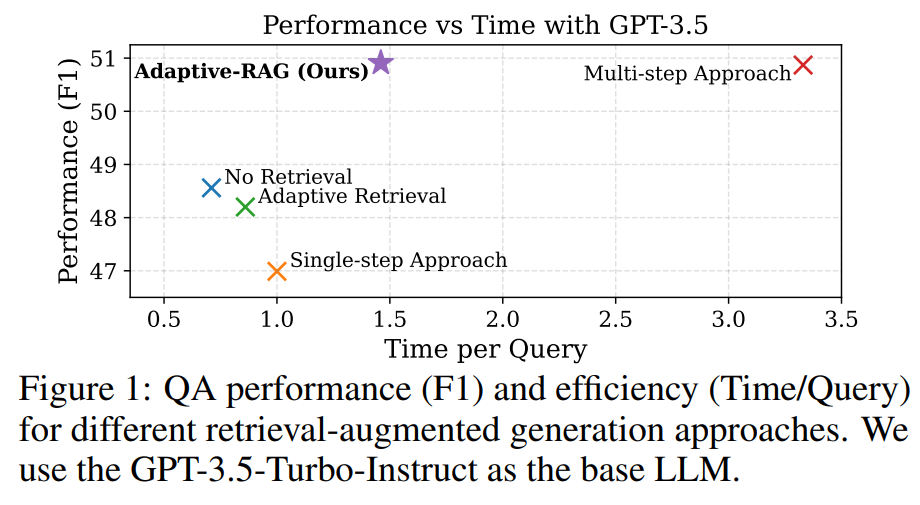
아래 표를 확인할 때, 서로 다른 카테고리의 모델은 직접 비교할 수 없다는 점에 유의해야 함

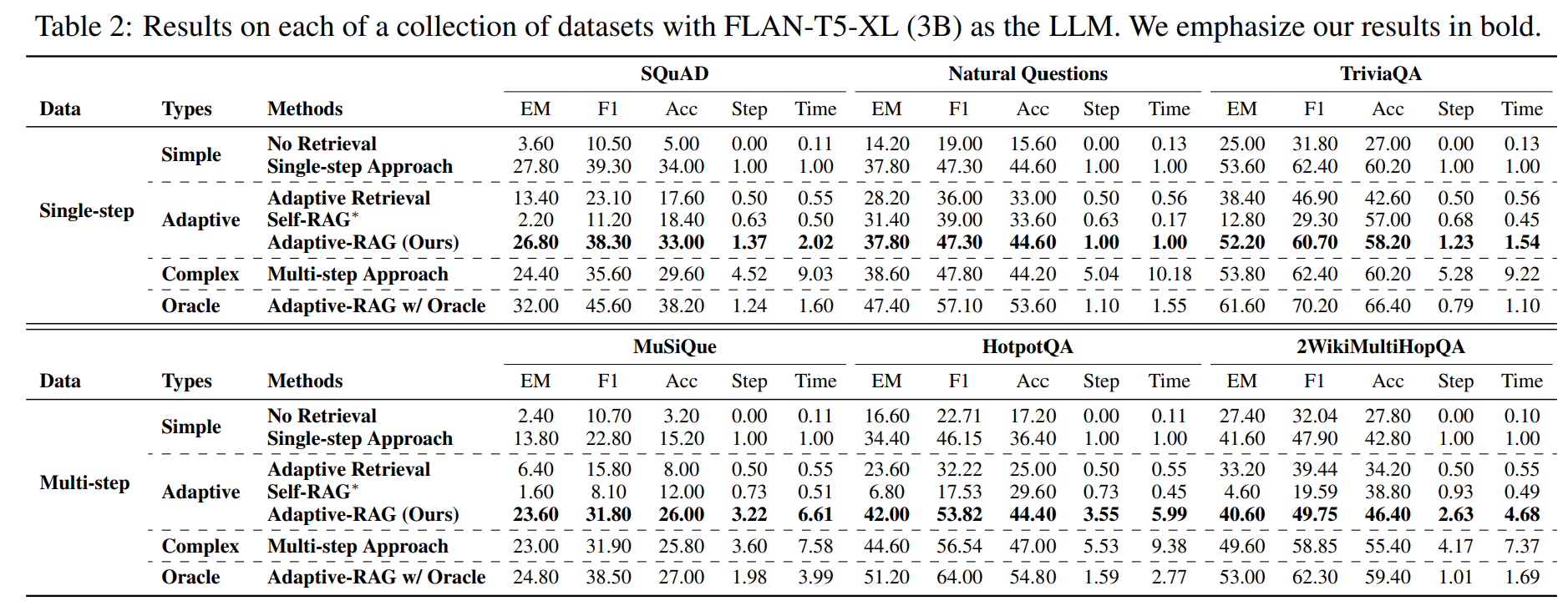
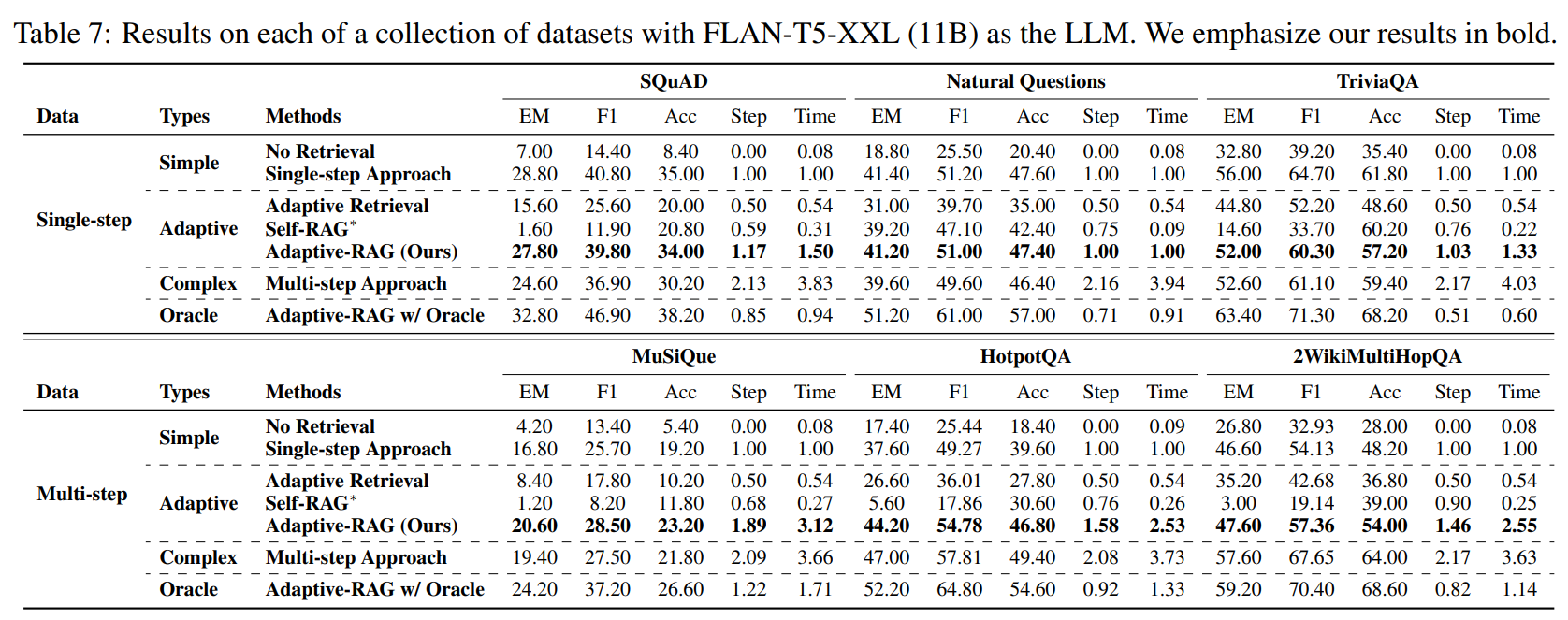
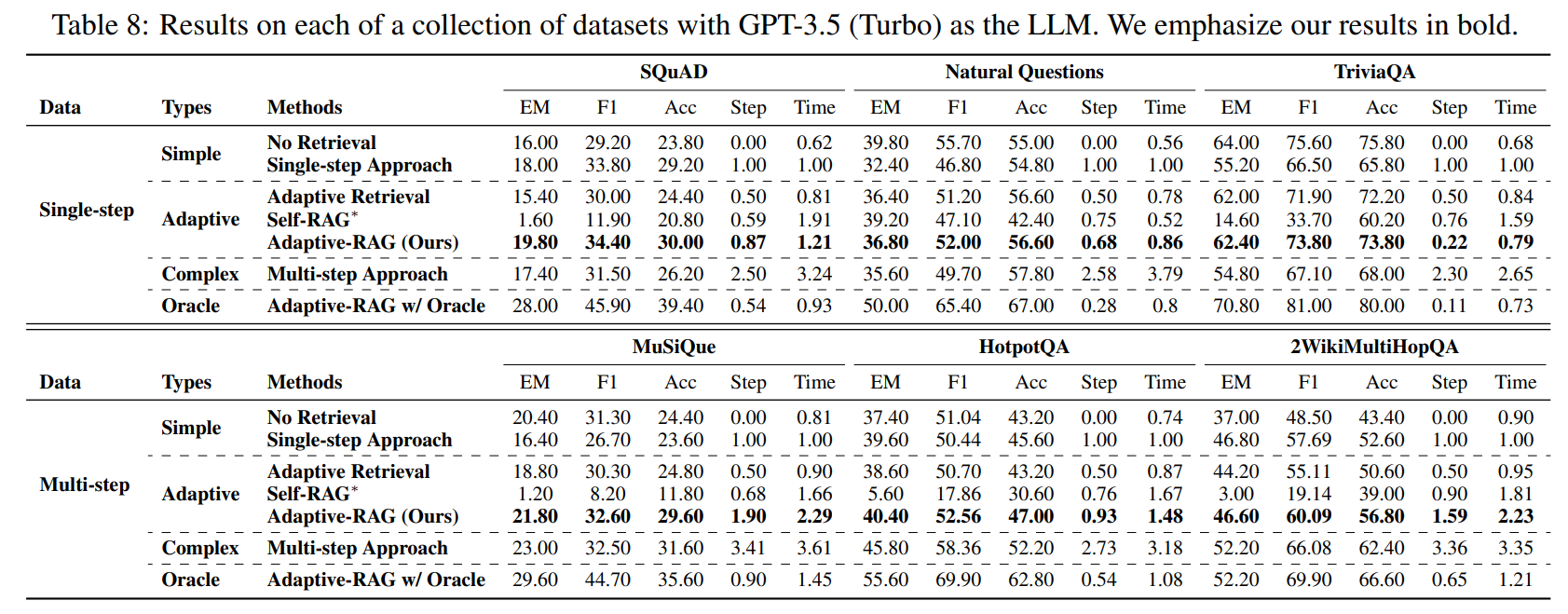
Classifier Performance

저자들은 저자들의 분류기가 세 가지 레이블을 효과적으로 분류하고 있음을 보여주지만, 이러한 오분류에 기반해 분류기를 더욱 세분화하는 것을 future work로 제시함
Analyses on Efficiency for Classifier
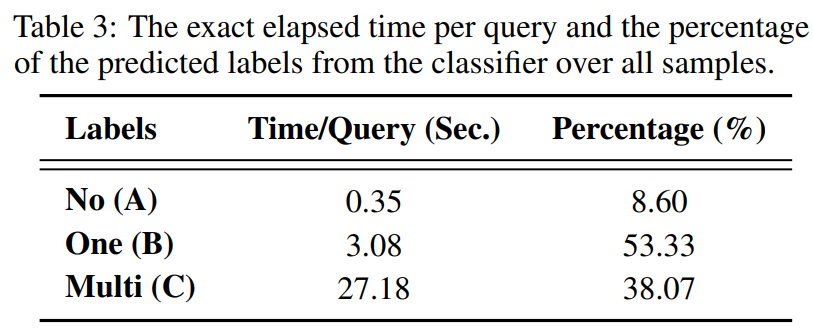
기존 Multi-step Approach에 비해, 단순하거나 간단한 쿼리를 식별함으로써 효율성을 크게 향상시킬 수 있음을 보여줌
Analyses on Training Data for Classifier
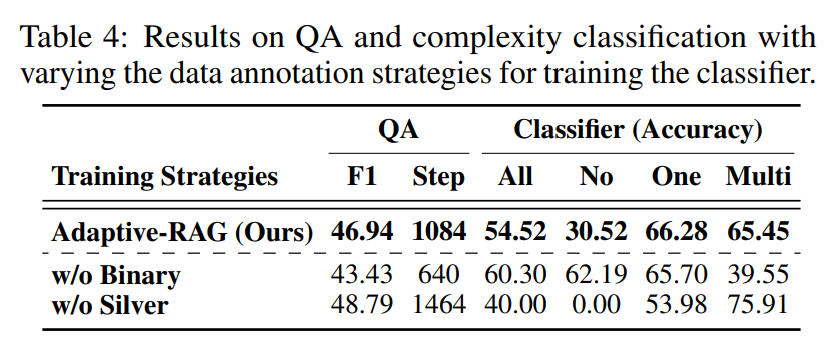
- 정확한 예측에서 주석이 달린 실버 데이터만 사용하는 경우 (Single/Multi-hop dataset 출처를 label로 사용하는 경우), 전체적인 분류 정확도는 높지만 전반적인 QA 성능은 실버 데이터에만 의존하는 것이 최적이 아닐 수 있음을 시사함
- 이는 실버 데이터가 잘못 예측된 쿼리에 대한 복잡도 레이블을 포함하지 않아 해당 쿼리와 관련된 쿼리에 대한 일반화 효과가 떨어지기 때문일 수 있다고 함
- 한편, 데이터 세트 편향(single-hop vs multi-hop)으로 인한 복잡도 레이블도 통합하면 분류기가 멀티 홉 쿼리를 더 정확하게 예측할 수 있어 성능이 향상된다고 함
Analyses on Classifier Size
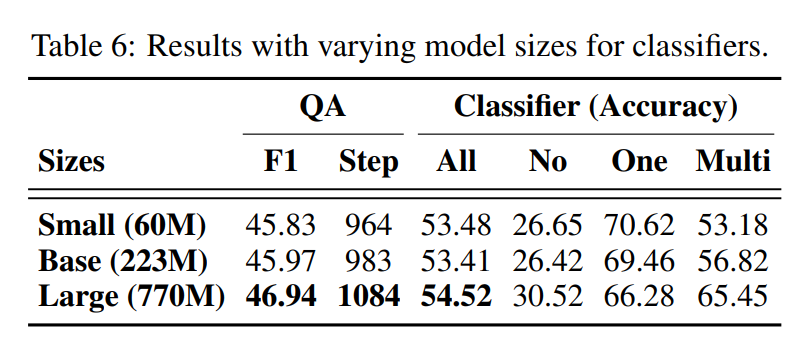
실제 사용 사례에서 제안한 Classifier를 더 작은 모델을 사용하더라도, 성능 저하 없이 리소스 효율성을 얻을 수 있을 것임
Case Study

먼저, 단순한 single-hop 질문의 경우, Adaptive-RAG는 'Google'에 대한 LLM의 파라메트릭 지식만으로 답변이 가능하다는 것을 식별하지만, Adaptive Retrieval은 추가 문서를 가져오기 때문에 처리 시간이 길어지고 'Microsoft'에 대한 부분적으로 관련 없는 정보가 포함되어 잘못된 응답을 생성하기도 한다.
한편, 복잡한 질문에 직면했을 때, Adaptive-RAG는 LLM에 저장되지 않았을 수 있는 '존 캐봇의 아들'과 같은 세부 정보를 포함해 관련 정보를 찾는 반면, Adaptive Retrieval은 외부 소스에서 이러한 정보를 요청하지 않아 부정확한 답변이 나온다.
6. Conclustion
Limitations
- Query Complexity Classifier를 Training Dataset과 아키텍처의 관점에서 개선할 수 있을 것임
- 기존 라벨링 프로세스는 쿼리에 잘못된 라벨을 붙일 가능성이 있음
- 향후 작업에서는 질문-답변 쌍의 라벨 외에도, 다양한 종류의 쿼리 복잡도 데이터셋을 생성할 수 있을 것임
- 이상적인 Classifier와 현재 Classifier 사이의 성능 격차에서 알 수 있듯이, Classifier의 효율성을 개선할 여지가 여전히 남아 있음
- 즉, 더 작은 LM을 기반으로 한 Classifier 설계는 쿼리 복잡도를 분류하기 위한 가장 간단한 초기 버전이며, 이를 기반으로 향후 작업을 통해 Classifier 아키텍처와 성능을 개선하여 전체 QA 성능에 긍정적으로 기여할 수 있을 것
- real-world setting에선 사용자의 입력이 불쾌하거나 유해한 경우가 있는데, 이때는 불쾌감을 주는 문서가 검색되고 검색된 문서에 의해 부적절한 응답이 생성될 수 있음
- 이 문제를 해결하려면 RAG 프레임워크 내에서 사용자 입력과 검색된 문서 모두에서 부적절한 콘텐츠를 감지하고 관리하는 방법을 개발하는 것이 필수적
Contribution
- real-world 환경에서 query의 다양한 복잡성 수준을 고려한 연구
- LLM과 Retriever의 내부 모델 아키텍처나 매개변수를 변경하지 않는 방법