
- Publication Info: TACL 2024
- arXiv: https://arxiv.org/abs/2307.03172
- code: https://nelsonliu.me/papers/lost-in-the-middle
심리학에는 서열 위치 효과(serial-position effect)라는 용어가 있다. 사람들은 어떠한 나열들을 기억할 때 처음과 끝의 내용들은 잘 기억하지만, 중간에 있는 내용들은 쉽게 기억하지 못하는 경향의 현상을 의미하는 용어이다.
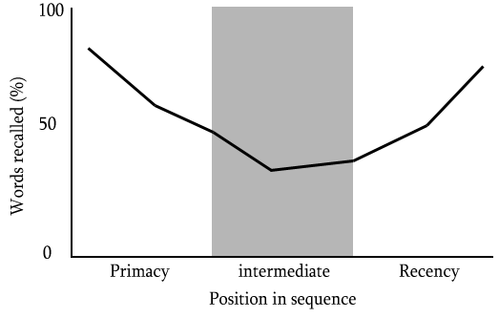
갑자기 웬 심리학인가 할수도 있지만, Lost in the Middle 논문은 이러한 서열 위치 효과 현상이 LLM에서도 발생하는지 실험적으로 분석했다. (저자들이 서열 위치 효과를 직접적으로 논문의 motivation으로 꼽은건 아니지만, 저자들도 이 효과에 대해 인지하고 있는 것 같다.)
Research Background
LLM이 In-context Learning 능력을 갖게 되며, prompting을 통해 downstream tasks를 푸는 것이 LLM의 트렌드가 되었다.
그리고 long documents를 처리해야 하는 도메인들 (legal, scientific documents, conversation histories, etc.) 때문이더라도, long contexts를 받아들일 수 있도록 언어모델들의 context length를 확장시켜 long context LLM (extended-context language models)를 만드는 노력이 계속되고 있다. (기존의 transformer는 512~2048 tokens로 학습이 되어왔지만, 얼마전 공개된 Llama 3.1은 context length가 128K이다.)
Research Question
Long Context LLM이 downstream task를 수행할 때 input context를 활용하는 방법은 무엇인가?
저자들은 위 RQ에 답하기 위해, multi-document QA task (e.g., RAG)에서 2가지 메인 포인트를 설정하여 실험을 설계했다.
- LLM의 입력으로 하는 input context의 길이를 바꾸었을 때 언어모델의 성능에 끼치는 효과 관찰
- Input context 안의 관련 정보의 순서(위치)를 바꾸었을 때 언어모델의 성능에 끼치는 효과 관찰
(가설: 만약 언어모델이 long input contexts 안의 정보를 robust하게 사용할 수 있다면, 관련 정보의 순서에 따른 성능 영향은 최소화될 것이다.)
Experiment: Multi-Document Question Answering
Experimental Setup
RQ에 대한 메인 실험에서 각각의 포인트에 대한 실험 환경 셋팅은 아래와 같다.
- Point 1 (context의 길이 변화)
- input context의 길이를 바꾸는 것은 RAG에서 검색할 문서의 수 ($k$)를 변화시키는 것으로 설정
- Point 2 (관련 정보의 위치 변화)
- 관련 정보는 질문에 대한 정답에 대한 정보를 얻을 수 있는 documents를 의미
- 관련 정보는 $k$개의 문서들 중 $1$건만 구성
- 즉, LLM에게 입력으로 제공하는 $k$개의 문서들 중 단 $1$건만 정답에 대한 정보를 얻을 수 있고, 나머지 $k-1$개의 문서들로부터 정답을 구할 수 없음
- 관련 정보와 다른 문서들의 순서를 바꿔가며 실험
Experimental Results
저자들은 input context에서 관련 정보의 위치를 바꾸는 것이 모델의 성능에 상당한 영향을 끼치는 것을 발견했다.
아래 그림은 $k=20$개의 문서들 중, 관련 정보의 순서를 1번부터 20번까지에 위치시켜놓고 multi-document QA task를 수행했을 때의 결과이다.

실험 결과, 정답과 관련된 정보가 input prompt의 초반이나 후반에 있을 때 성능이 우수하고, 관련 정보가 중간에 있을 때는 낮은 성능을 보였다.
빨간 점선은 아무런 document를 주지 않고, LLM의 parametric memory 만으로 문제를 풀게 시키는 closed-book setting에서의 성능 결과인데, 정답 관련 정보가 중간에 있을 때는 closed-book setting에서의 성능보다도 못한 결과가 나오는 것을 확인할 수 있다.
즉, 'Long Context LLM 및 input context를 사용하는 것이 항상 더 좋은 것은 아니다'라는 것을 보여준다.
Experiment: How Well Can Language Models Retrieve From Input Contexts?
그렇다면, 언어 모델은 Input Contexts에서 정보를 얼마나 잘 검색할 수 있을까?
Experimental Setup
저자들은 아래 그림처럼 임의의 key-value pair를 포함하는 JSON을 LLM에 입력으로 제공하고, LLM에게 특정 key에 해당하는 value를 반환하는 과제를 설계했다. (Input key-value pair 데이터의 개수는 75, 140, 300으로 설정)
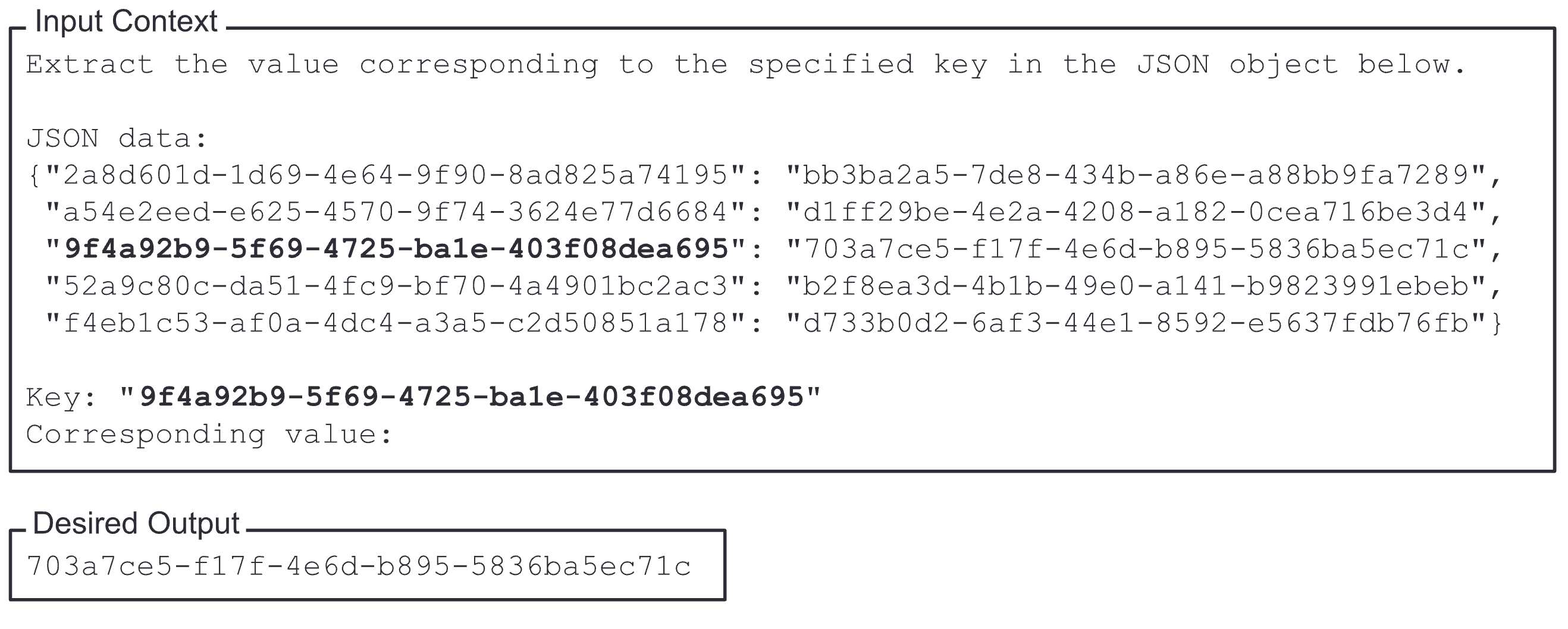
Experimental Results
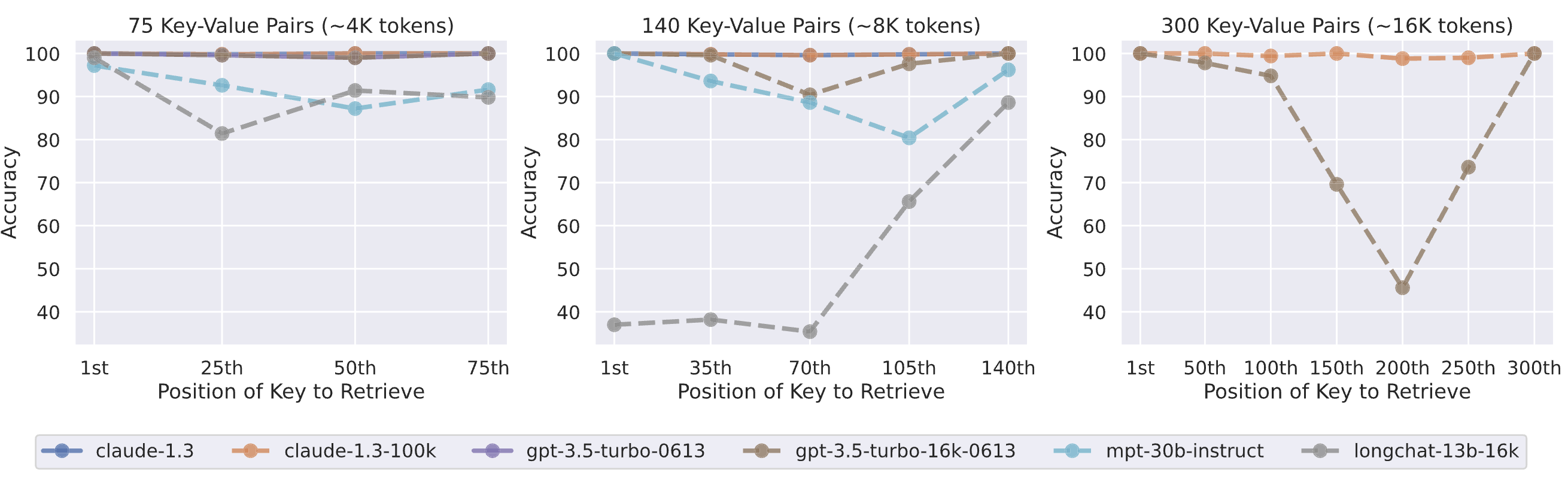
- Claude-1.3 및 Claude-1.3 (100K)은 모든 평가 입력 길이에 대해 거의 완벽한 성능을 보인다.
- 다른 모델들은 key-value pair data가 140, 300개일 때 성능이 낮다.
- GPT-3.5-Turbo와 MPT-30B-Instruct는 context 중간에 위치한 key-value pair를 검색할 때 성능이 저조하다.
- LongChat-13B (16K)는 140개 세팅에서 다른 트렌드를 보이며, 시작 부분에 위치한 정보를 검색할 때 코드 생성을 시도했다고 한다.
Additional Studies:
Why Are Language Models Not Robust to Changes in the Position of Relevant Information?
그렇다면 언어 모델이 관련 정보의 위치 변경에 민감한 이유는 무엇일까? 저자들은 이 질문에 답하기 위해 3가지 관점에서 추가적인 분석을 수행한다.
- 모델 아키텍처의 영향 (decoder-only vs. encoder-decoder)
- Query-aware contextualization (질문 데이터를 처리할 문서나 key-value pair 앞뒤에 배치하여, 문서 또는 key-value pair를 문맥화할 때 질문을 참고할 수 있게 하는 방법)
- Instuction fine-tuning의 유무
Additional Study (1): 모델 아키텍처의 영향
중요한 관련 정보가 가운데로 가면 성능이 떨어지는 이유가 모델 아키텍쳐 때문일까?
참고로, 모델 아키텍쳐 별로 아래와 같은 특징을 가진다.
- Decoder-only 모델 (e.g., mpt-30b-instruct, longchat-13b-16k)
- 입력 context 내 이전 토큰들만을 참고할 수 있으며, 정보 위치에 따라 성능이 달라짐
- Encoder-decoder 모델 (e.g., flan-t5-xxl, flan-ul2)
- 양방향으로 context를 처리할 수 있어 정보 위치 변화에 덜 민감함

결론: 그러나 모델 아키텍쳐에 관계 없이 Retrieved Documents의 개수($k$)가 많아질수록 Lost in the Middle 현상은 여전히 발생.
Additional Study (2): Query-aware contextualization
메인 실험에서는 아래 그림처럼, Question을 Documents 뒤에 위치시켜 Input Prompt를 구성했다.

그리고 메인 실험에서 사용한 GPT-3.5나 Claude 같은 모델들은 모두 decoder-only 모델들이었다.
그런데 잠깐. Decoder-only 모델들은 Documents를 읽을 때, Question이 무엇인지 모르기 때문에 attention score에 영향이 갈 수도 있을 것이다.
그렇다면 Question을 Documents 앞에 위치시켜보면 성능이 달라질까?
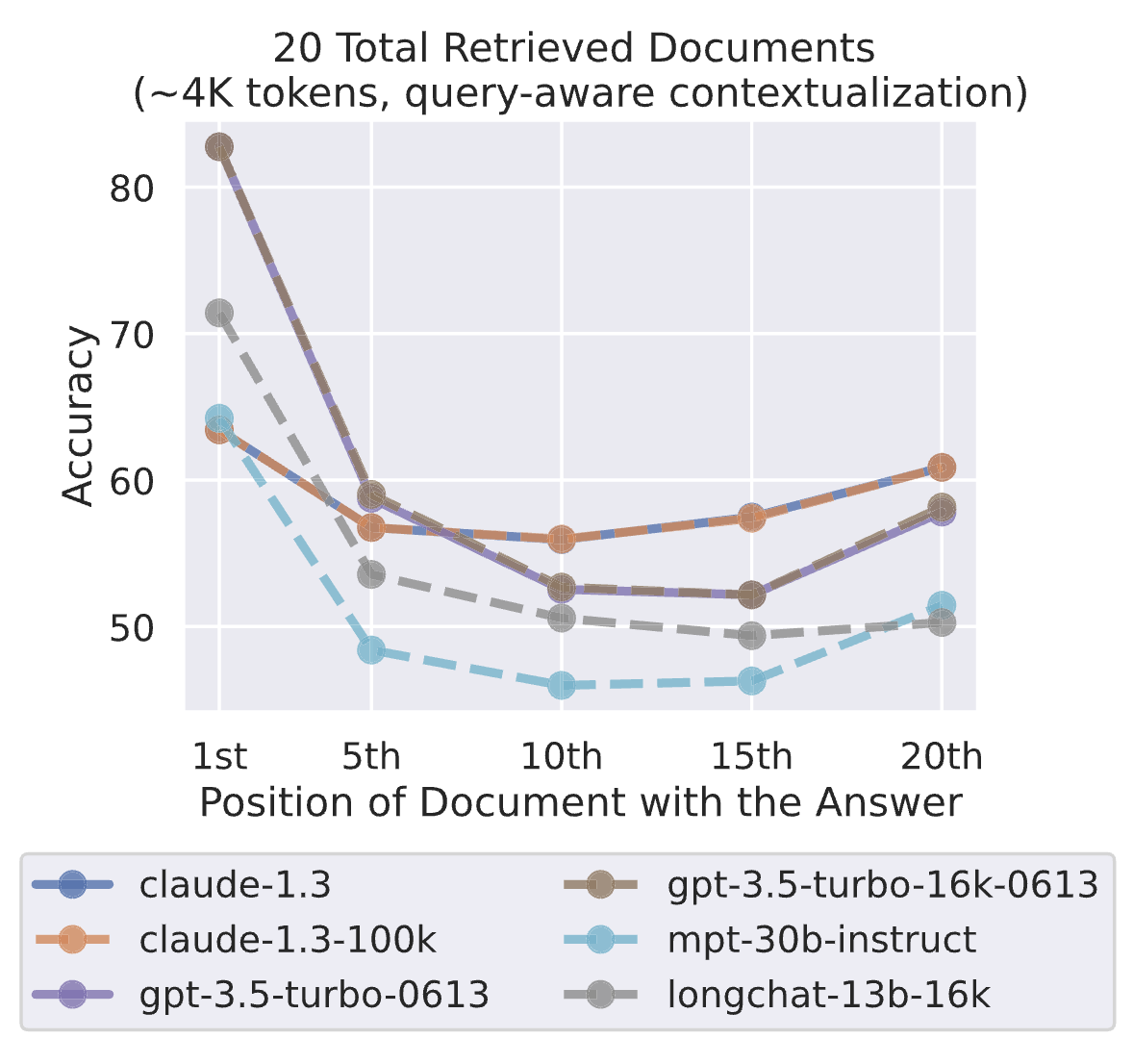
- Query-aware contextualization의 이점: key-value 검색 작업의 성능을 극단적으로 향상시킨다.
- 예를 들어 GPT-3.5-Turbo (16K)는 Query-aware contextualization을 통해 300개의 key-value pair 셋팅에서 완벽한 성능을 보였다.
- 문서 질의 응답 작업에서는 성능 향상이 적었는데, 질문이 입력 컨텍스트의 맨 처음에 위치할 때 성능이 약간 향상되었으나, 다른 셋팅에서는 성능이 약간 감소했다.
- 실험 결과
- Key-value retrieval task에서는 성능이 극단적으로 향상된다.
- 그러나 Multi-document QA task에서는 큰 성능 향상이 없다. 즉, 여전히 Lost in the Middle. (아래 Figure 9 참조)
Additional Study (3): Instuction fine-tuning의 유무
Instruction-tuning을 통해 Align 된 답변을 생성하다보니, 이런 현상이 발생하는건 아닐까? 저자들은 Instruction-tuning이 되지 않은 Base LLM과 Instruction-tuned LLM을 비교해본다.

- 결론: Instruction-tuning은 모델 자체의 Accuracy를 향상시키는 효과만 있을 뿐, Lost in the Middle 현상은 Instruction Fine-tuning의 유무와 상관없이 발생한다.
Conclusion
RAG에서 문서의 순서가 중요하다. 특히, 중요한 정보가 가운데 있을 때, 성능 하락이 있음을 확인하였다.
이는 현재의 언어 모델들이 긴 문맥에서 정보를 잘 사용하지 못한다는 것을 의미한다.
향후, long context models를 평가할 때, 이러한 점을 고려한 새로운 evaluation protocol이 필요할 것이다.
참고하면 좋을 다른 논문들
- (ACL Findings 2024) Found in the Middle: Calibrating Positional Attention Bias Improves Long Context Utilization
- (Anthropic 2024) Introducing the next generation of Claude; Long context and near-perfect recall
- (arXiv 2024) Retrieval Augmented Generation or Long-Context LLMs? A Comprehensive Study and Hybrid Approach
- (arXiv 2024) Make Your LLM Fully Utilize the Context
- (arXiv 2024) Summary of a Haystack: A Challenge to Long-Context LLMs and RAG Systems
- (ICLR 2024) Retrieval meets Long Context Large Language Models