
반응형
GPL: Generative Pseudo Labeling for Unsupervised Domain Adaptation of Dense Retrieval
- Cited by 142 (’2024-10-22)
- Publication Info: NAACL 2022
- URL: https://aclanthology.org/2022.naacl-main.168
GPL: Generative Pseudo Labeling for Unsupervised Domain Adaptation of Dense Retrieval
Kexin Wang, Nandan Thakur, Nils Reimers, Iryna Gurevych. Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2022.
aclanthology.org
Summary
- GPL이라는 Unsupervised Domain Adaptation 방법을 제안하고, 기존 domain adaptation method와 광범위하게 성능 비교 (nDCG@10)
Problem
- Dense retrieval는 대부분의 도메인에서 사용할 수 없는 대량의 학습 데이터가 필요로 함
- Dense retireval은 domain shifts에 매우 민감함
- MS MARCO에서 훈련된 모델은 코로나19 과학 문헌에 대한 질문에 대해 다소 저조한 성능을 보임
- MS MARCO는 코로나19 이전에 생성되었기 때문에 코로나19 관련 주제가 포함되어 있지 않으며, 모델은 이 주제를 vector space에서 잘 표현하는 방법을 학습하지 못했기 때문
Related Work
- Dense retrieval의 성능은 domain shift를 거치면 하락함이 이전 연구를 통해 밝혀짐
Contribution
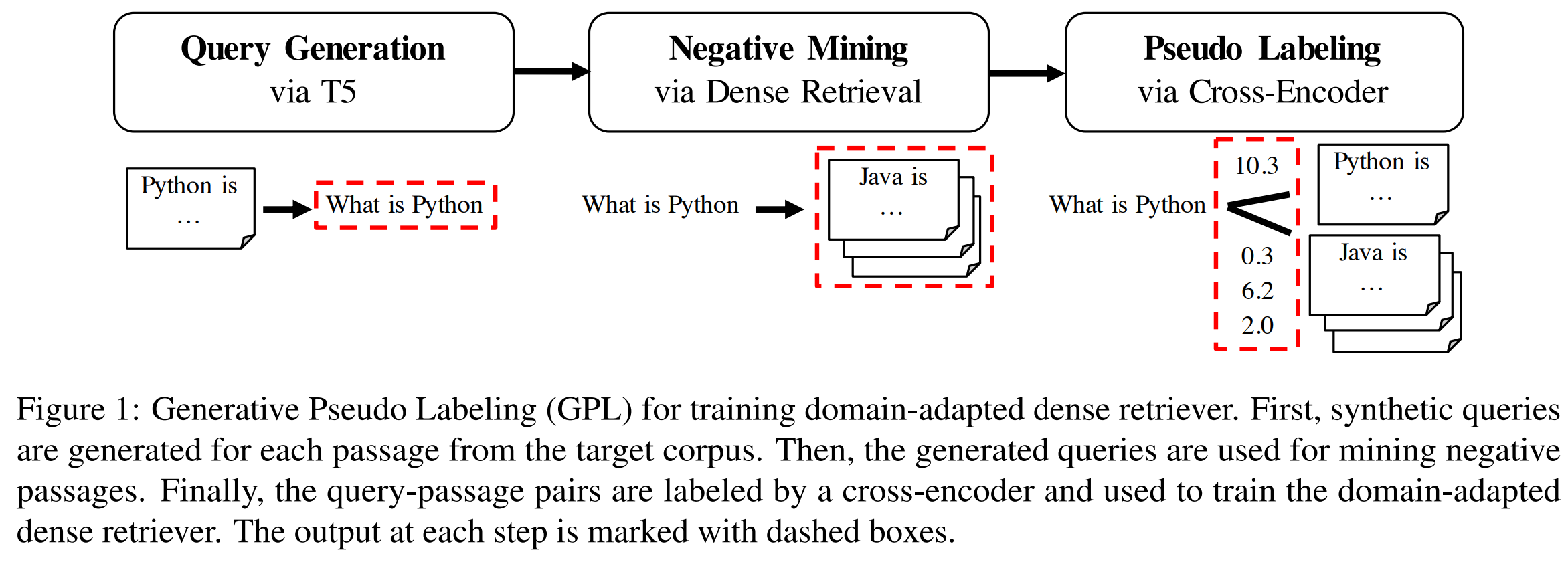
- unsupervised domain adaptation 방법론인 query generator와 cross-encoder의 pseudo labeling을 결합하는 방식의 Generative Pseudo Labeling (GPL)을 제안
- 원하는 도메인의 passages에 대해 pre-trained T5로 합성 쿼리를 생성
- 합성 쿼리 생성에 사용된 passages는 생성된 쿼리에 대해 positive passages로 간주
- negative mining; 기존의 dense retrieval model로 생성된 쿼리와 가장 유사한 passages를 찾아 그것을 negative passages (hard negative)로 간주
- cross-encoder를 사용하여 각 (query, passage) 쌍에 점수를 매기고, MarginMSE-Loss를 사용하여 생성된 pseudo-labeled queries에 대해 dense retrieval model을 훈련
- GPL을 Previous Domain Adaptaion Models와 비교
- Previous Domain Adaptation Methods
- UDALM, MoDIR
- Pre-Training based Domain Adaptation
- CD, SimCSE, CT, MLM, ICT, TSDAE
- Generation-based Domain Adaptation
- QGen, QGen (w/ Hard Negatives)
- Previous Domain Adaptation Methods
Exp - Dataset
- six representative domain-specific datasets from the BeIR benchmark
- FiQA (financial domain)
- SciFact (scientific papers)
- BioASQ (biomedical Q&A)
- TREC-COVID (scientific papers on COVID-19)
- CQADupStack (12 StackExchange subforums)
- Robust04 (news articles)
Limitation
- catastrophic forgetting 분석 x
반응형