
arXiv: https://arxiv.org/abs/2410.07176
OpenReview: https://openreview.net/forum?id=xy6B5Fh2v7
Code: x
Keywords: Retrieval Augmented Generation, Knowledge Conflicts
1. Motivation
- 검색 결과에 의존하는 RAG는 관련성이 없거나 오해의 소지가 있는 불완전한 검색 결과로 인해, 부정확한 LLM 응답을 초래할 수 있음
- 검색된 결과가 LLM이 알고 있던 지식과 다를 때는 Knowledge Conflict가 발생할 수 있지만, 대부분의 기존 연구들은 이를 고려하지 않음

2. Preliminary Experiment: Imperfect retrieval is common
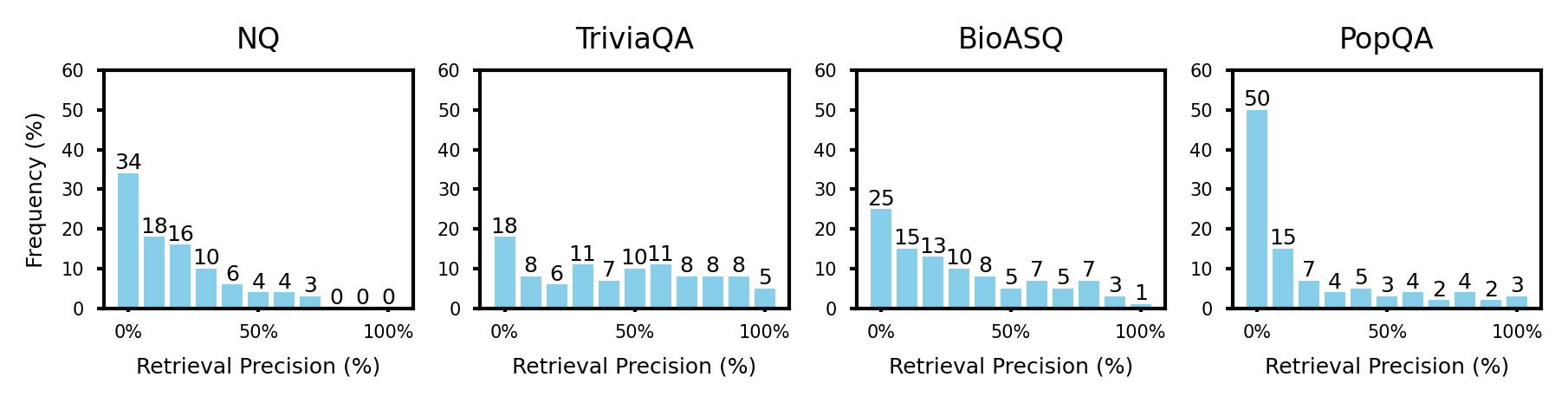
$$Retrieval\ Precision=\frac{\#\ retrieved\ passages\ containing\ correct\ answer}{\#\ total\ retrieved\ passages}$$
3. Problems & Previous Works
Problems
- 불완전한 검색 결과 및 Knowledge Conflicts는 광범위하게 발생하고, 이것들은 RAG의 오류를 초래함
- 기존 연구들에 따르면, LLM은 Knowledge Conflict 상황에서 내·외부 지식을 종합적으로 이해하기보다는 잘못된 정보에 기반하여 답변하는 경향이 있음 [1-3]
Previous Works
-
- 검색 결과에 초점을 둔 이전 연구들과[1,4] 달리, 본 논문은 검색된 passage가 제공된 검색 후 단계에서 LLM 내부 지식을 활용하여 RAG의 견고성을 강화하는 데 중점을 두고 있음
- 또한, Black-Box 환경에서 training 없이 knowledge conflicts를 직접 해결하여 양쪽의 유용한 정보를 결합하고, 보다 신뢰할 수 있는 답변을 얻을 수 있는 방법을 제안함
- 그렇다면, 신뢰할 수 있는 RAG를 위해, LLM의 내·외부 지식 충돌을 해결하는 방법이 있는가?
4. Methods
Overview
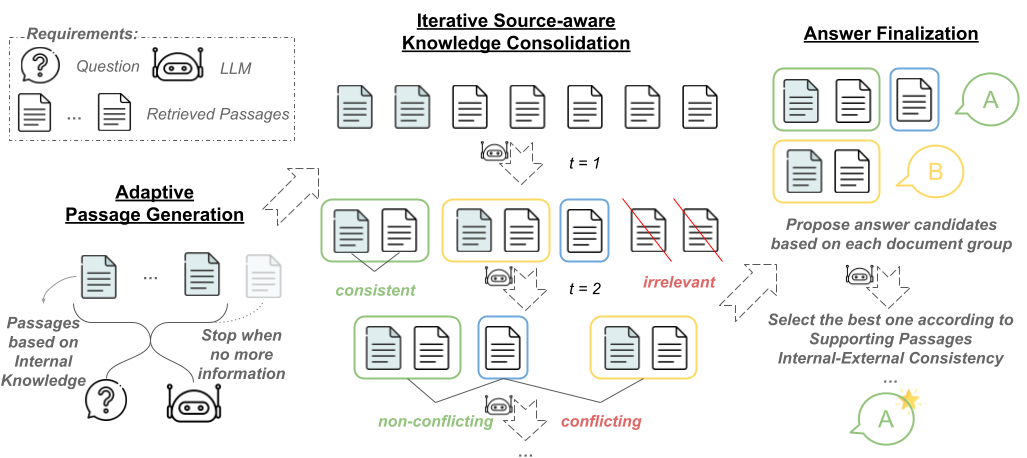
Step 1/3: Passages Generation of Internal Knowledge
- LLM의 내부 지식을 명시적으로 도출
- question $q$를 기반으로 여러 개의 passages를 생성하도록 LLM prompting
- LLM 내부 지식과 외부 지식 간의 상호 확인을 위한 목적

Step 2/3: Iterative Source-aware Knowledge Consolidation
- 내·외부 지식 정보들을 한번에 비교하여 context를 명시적으로 통합하도록 LLM prompting
- 일관된 정보 → cluster & summarize
- 정보 간 충돌 → separate
- 불필요한 정보 → exclude
- LLM이 지식을 통합할 때, 각 지식의 출처를 함께 제공
- Memory or Internal
- 위 과정을 $t$번 반복하여 더 유용한 contexts로 개선함

Step 3/3: Step Answer Finalization
- 각각의 그룹으로부터 답변을 하나씩 생성한 후, 신뢰성을 고려하여 하나의 최종 답변을 선택하도록 LLM prompting
- 신뢰성 평가에는 지식 출처, 출처간 정보 일치 여부, 정보 세밀성 등을 고려

5. Experimental Settings
Dataset
NQ, TriviaQA, BioASQ, PopQA → 짧은 형식의 QA 데이터셋
Passage Collection
- 각 질문에 대해 Google Search API를 통해 상위 30개의 결과를 검색
- 접근 가능한 상위 10개의 웹사이트를 선택
- 검색 결과의 snippet에 해당하는 단락을 각 웹사이트에서 추출하여 passage로 사용
Metric
Accuracy; 모델의 응답이 실제 정답을 포함하고 있으면 정확한 것으로 간주
LLM Parameters
- LLM: gemini-1.5-pro-002, claude-3-5-sonnet@20240620
- temperature: 0
- max_token: 1024
- # shot: zero-shot
Baselines
- USC (universal self-consistency) [5]
- 모든 LLM 응답을 여러 번 샘플링하여 평균을 냄 (기본적인 API 호출을 통한 단순 개선 방법)
- GenRead [6]
- LLM 내부 지식으로 생성한 문서로 답변함 (외부 지식을 사용하지 않음)
- RobustRAG [7]
- 각각의 독립적인 문서에서 답변을 생성하고, 키워드로 최종 답변을 집계함
- InstructRAG [8]
- 답변 생성 시, Rationale을 생성하는 RAG 방법
- Self-Route [9]
- 답변 시, RAG/LLM을 adaptive하게 선택하여 전환함 (내부 및 외부 지식 간의 전환)
6. Main Results
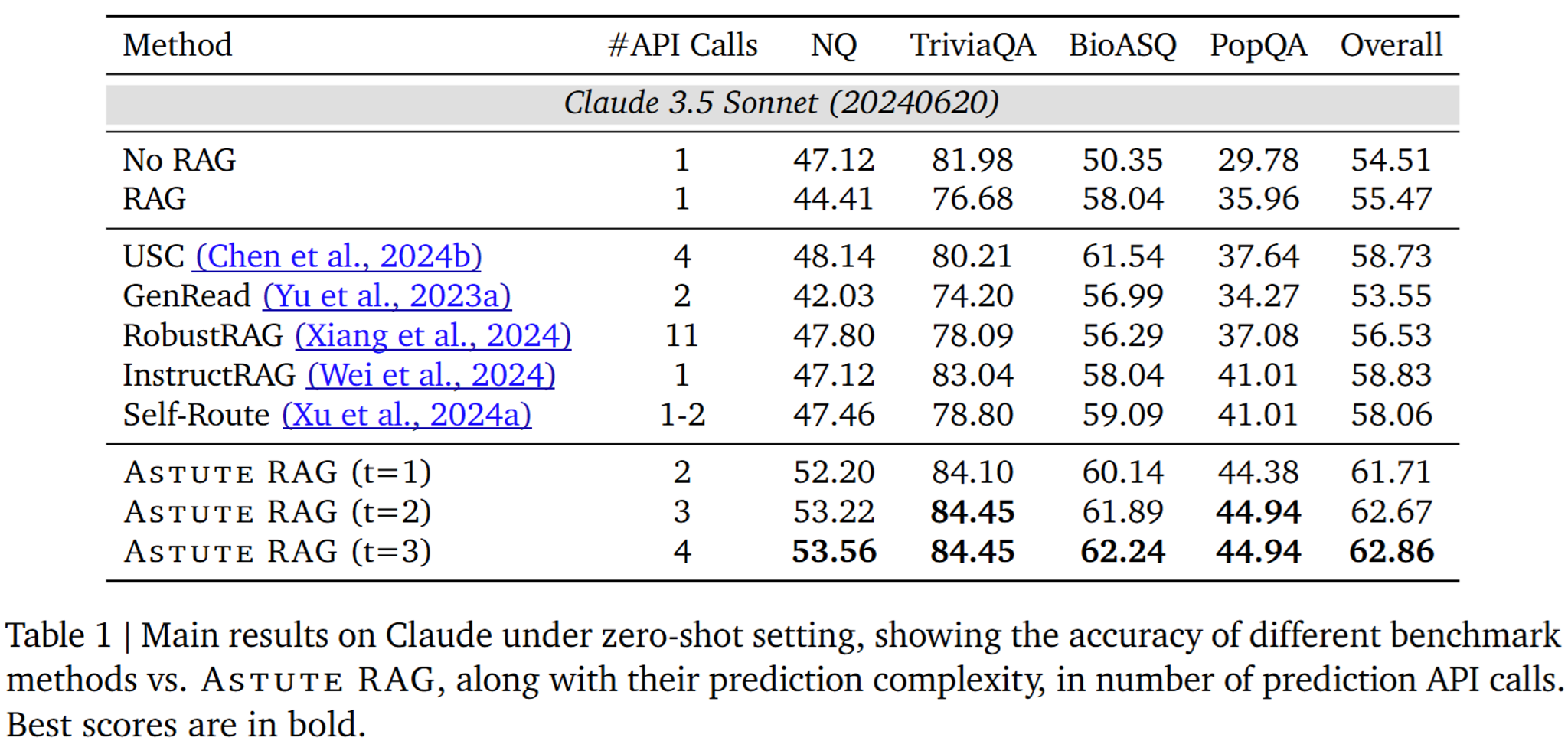
- No RAG vs. RAG : NQ나 TriviaQA 같은 데이터셋에서는 RAG를 쓰지 않는게 성능이 더 좋을 때도 있음
- 이는 검색 결과와 LLM 간의 지식 충돌 때문으로 보임
- 반면, domain-specific QA 및 long-tail QA인 BioASQ와 PopQA에선 RAG가 LLM의 성능을 향상시킴
- 베이스라인들 중에선 일관되게 성능이 높은 모델이 없음
- 이는 baseline 모델이 특정 setting에 fitting되어 있고, 보편적으로 적용되기에는 어렵다는 것을 시사함
- 반면, Astute RAG는 모든 데이터셋에서 일관되게 baseline을 능가함
- knowledge consolidation의 반복 횟수인 t를 늘리면 성능 개선 폭이 줄어드는데, 이것은 반복할수록 통합할 정보들이 줄어들기 때문
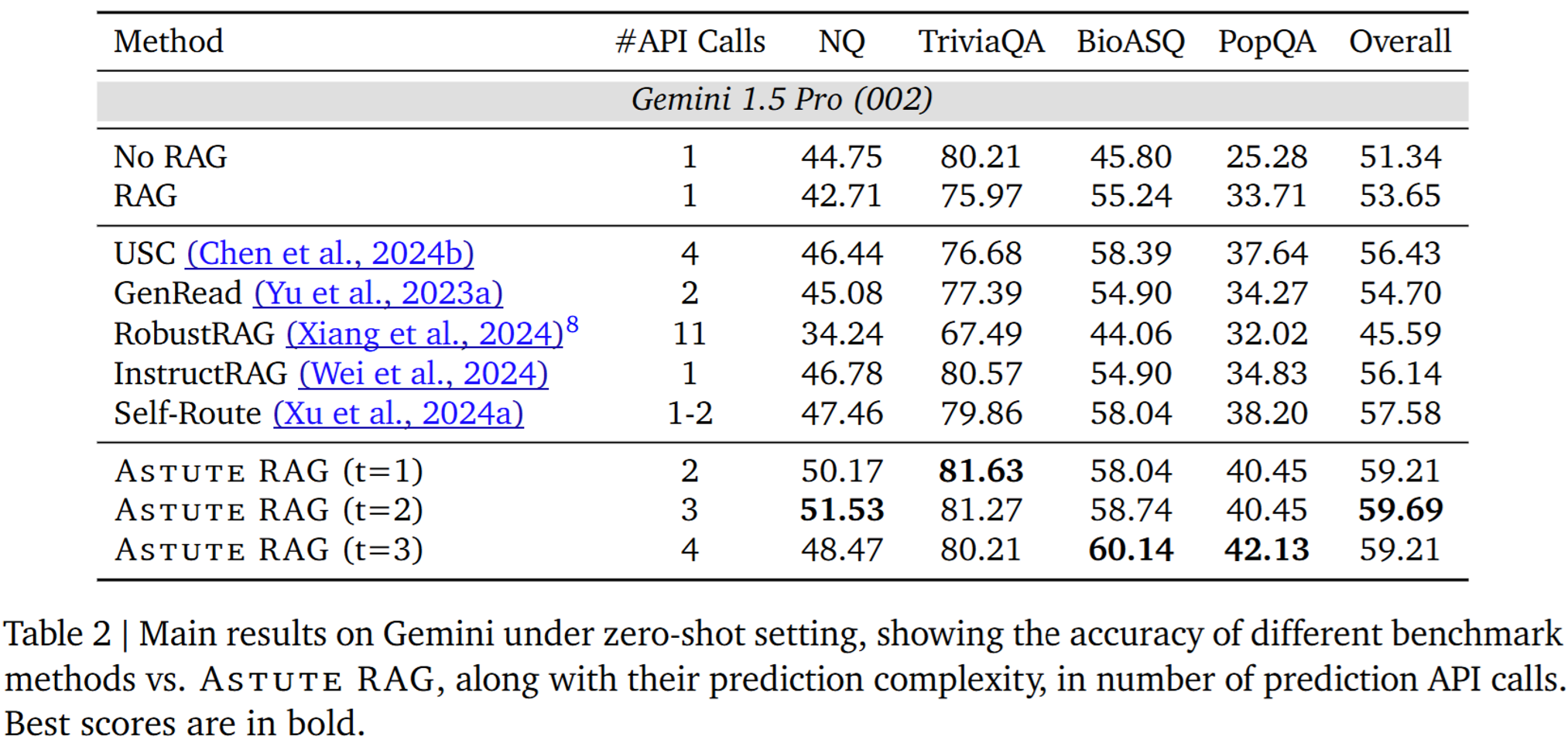
- Gemini에서 t를 늘리면 BioASQ와 PopQA의 성능이 증가함
- 두 데이터셋은 외부 지식에 더 많이 의존하는데, knowledge consolidation 과정을 반복하면 외부 정보 내의 노이즈를 완화하는 데 도움이 되기 때문
- t가 3에 도달하면 NQ와 TriviaQA의 성능은 더 이상 향상되지 않음
- 이 두 데이터셋에서는 외부 지식의 역할이 덜 중요하기 때문
7. Analyses
Performance by Retrieval Precision
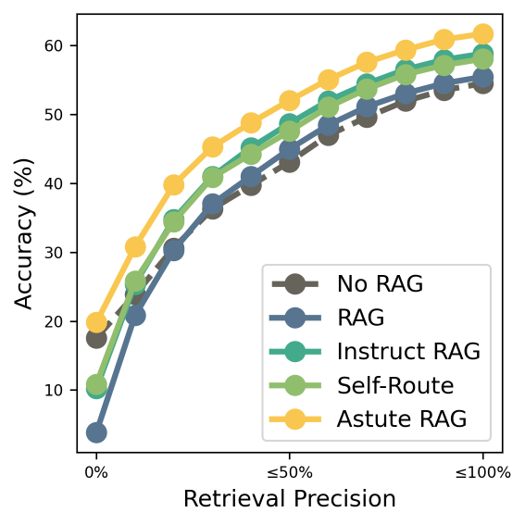
검색 품질이 매우 낮은 경우(Retrieval Precision이 거의 0에 가까울 때) 다른 베이스라인 모델들은 No RAG에 비해 성능이 저하된 반면, Astute RAG만이 이 기준을 넘는 성능을 보임
Performance by Knowledge Conflicts
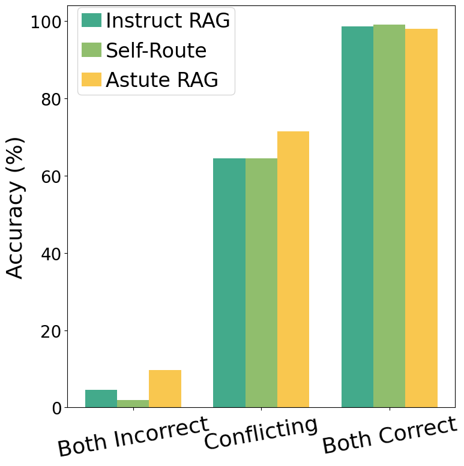
8. Conclusions
- 별도의 훈련 없이 Knowledge Confliction을 완화하기 위한 Astute RAG 제안
- LLM의 내부 지식을 활용하여 생성된 응답을 반복적으로 개선
- 내·외부 지식을 출처 기반으로 통합하여 답변을 최종화
- Limitations
- LLM의 Instruction-following 능력이나 Reasoning 능력에 의존함
- Knowledge Consolidation 시, LLM의 내재적 편견과 환각이 발생할 수 있음
- Main Results에서 API Call을 비교하는 것은 의미가 없어 보임
- API Call에 사용한 token 수를 비교해야 함
References
[1] (LREC-COLING 2024) Tug-of-War between Knowledge: Exploring and Resolving Knowledge Conflicts in Retrieval-Augmented Language Models
[2] (ACL 2024) Blinded by Generated Contexts: How Language Models Merge Generated and Retrieved Contexts for Open-Domain QA?
[3] (ICLR 2024) Adaptive Chameleon or Stubborn Sloth: Revealing the Behavior of Large Language Models in Knowledge Conflicts
[4] (ACL 2024) When Not to Trust Language Models: Investigating Effectiveness of Parametric and Non-Parametric Memories
[5] (ICML Workshop 2024) Universal Self-Consistency for Large Language Models
[6] (ICLR 2023) Generate rather than Retrieve: Large Language Models are Strong Context Generators
[7] (arXiv 2024) Certifiably Robust RAG against Retrieval Corruption
[8] (arXiv 2024) InstructRAG: Instructing Retrieval-Augmented Generation via Self-Synthesized Rationales
[9] (EMNLP Industry 2024) Retrieval Augmented Generation or Long-Context LLMs? A Comprehensive Study and Hybrid Approach